Merhaba,
<Resimleri büyütmek için tıklayınız..>
Bu yazımızda “where” cümleciği ile index tanımlanmış kolonların olduğu yapı ile tanımlanmamış olan kolonlarda yapılan işlemler arasındaki performans farkını anlatıyor olacağız.
Filtreli index Sql Server 2008 ile duyurulmuş bir özellik olup veritabanı yapısınına göre kullanılmasında performans artışı sağlayan bir özelliktir.Non-Clustered index uygulanan kolon üzerinde tanımlanır,tek farkı bunu yaparken where clause kullanacağız.Tahmin edeceğiniz üzere de tanımlayacağımız index daha az veri tutacağı için normal tanımlanmış non-clustered inexlere göre daha performanslı olacaktır.
Şimdi senaryo gereği,içinde çeşitli verilerin tutulacağı kolonları olan bir tablo oluşturuyoruz.İsim,Soyisim ve Ulus kolonlarının olduğu bir tablo olacak bu.İlk 100 kaydı isterseniz generatedata.com sitesinden aşağıdaki şekilde doldurarak elde edebilirsiniz.İlk 100 kayıt diyorum çünkü ona izin veriyor ücretsiz olarak 🙂 ;

“Generate” dedikten sonra size verilen scripti,editöre alıp execute etmeniz yeterli.
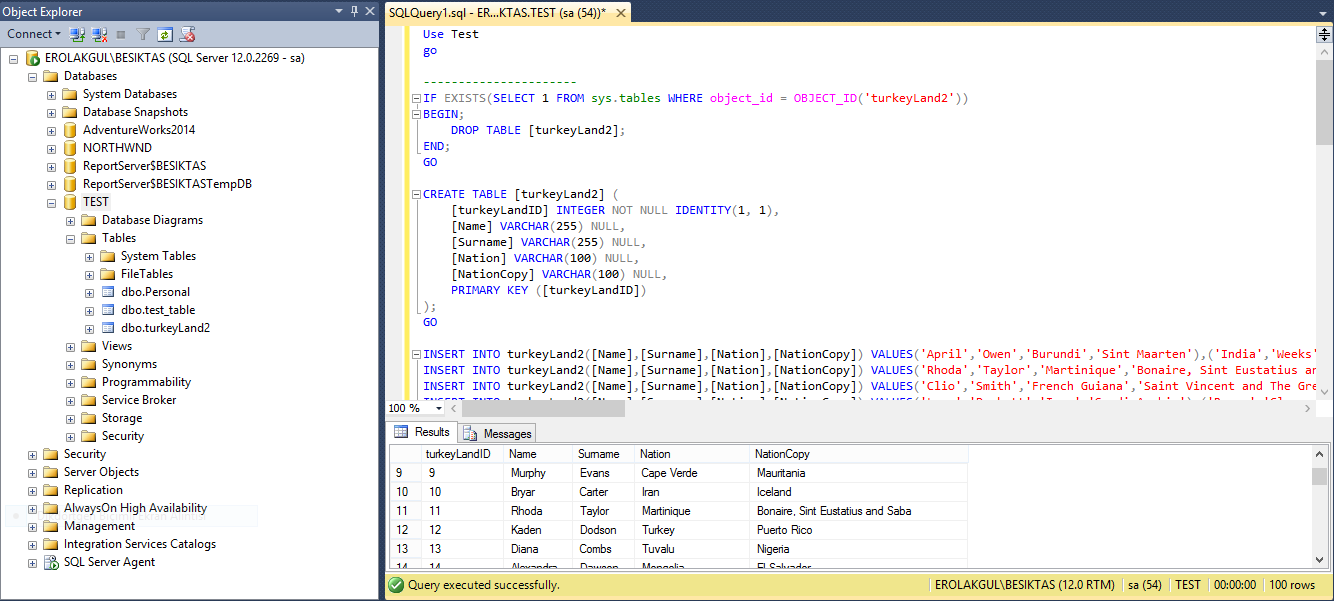
İşinize daha sonra yarayabilecek bu bilgiden sonra 100binlik bir kayıt girmek için kendimiz query yazıyoruz. ;
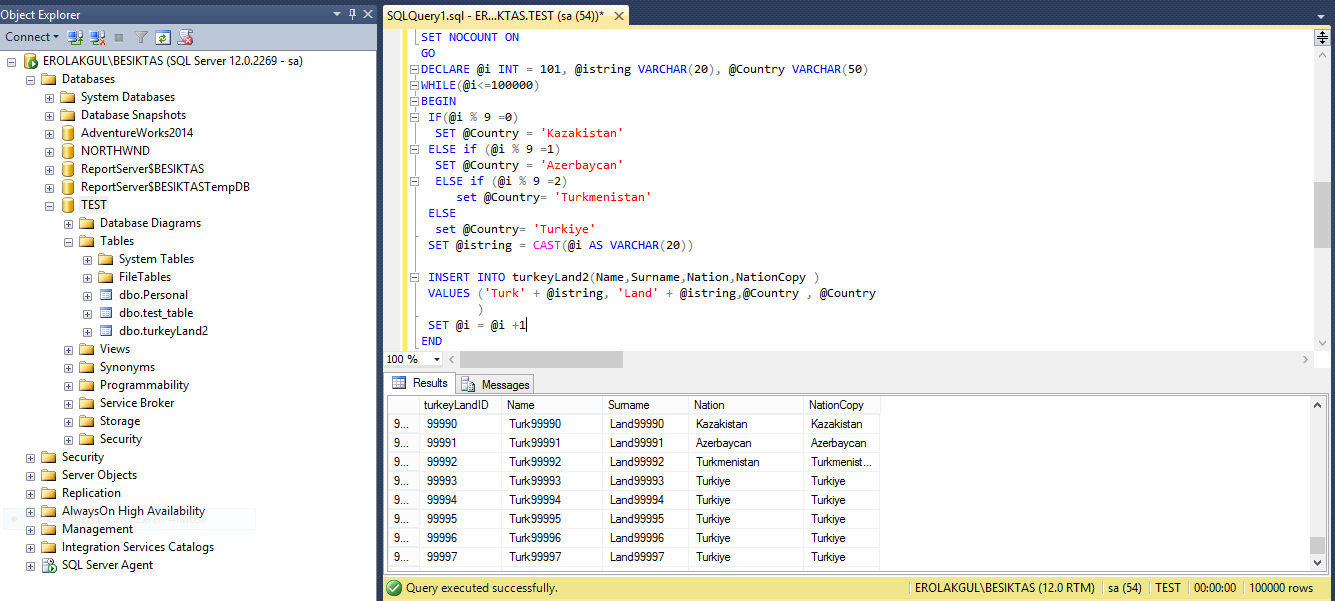
Döngü ile döngü sayısının mod’larına göre 4 farklı ülke ismi girmiş olduk.Tabloda şuan sadece clustered index var o da ID üzerine tanımlı bir şekilde.
Şimdi de sırasıyla non-clustered index leri tanımlayalım ;
İndexleri tanımlarken şöyle bir hata aldım “Msg 1101, Level 17, State 12, Line 61”..Yetersiz disk alanı yüzünden işlemi gerçekleştiremedi. MDF için 10mb, LDF için 1mb ‘lık alan vermiştim recovery model de full’de olduğundan toplu işlemler yapıldığında bu uyarıyı almak normal sanırım,MDF için 20,LDF için 4 Mb a çıkarıp sql server ı restart ederseniz indexleri oluştururken hata almazsınız..

Indexleri oluşturduk ve şuan tablomuzda 3 index var,ID üzerinde primary key olarak atadığımız Clustered index,Nation üzerinde non-clustered index ve NationCopy üzerinde ‘Azerbaycan’ yazan yerler üzerine uyguladığımız filtreli non-clustered index…
Sorgu sonucunda hangi indexin kaç satır veriyi kapsadığını ve toplamdaki page sayısını da bu şekilde görebiliyoruz.Her bir page 8kb lık veriyi içermektedir.Dolayısıyla filtreli indexin depoladığı verinin ne kadar azaldığını da görebiliyoruz buradan.
Şimdi de Nation ve NationCopy kolonlarında ‘Azerbaycan’ ı kapsayacak şekilde sorgularımızı atalım ve maliyetlerini görelim ;
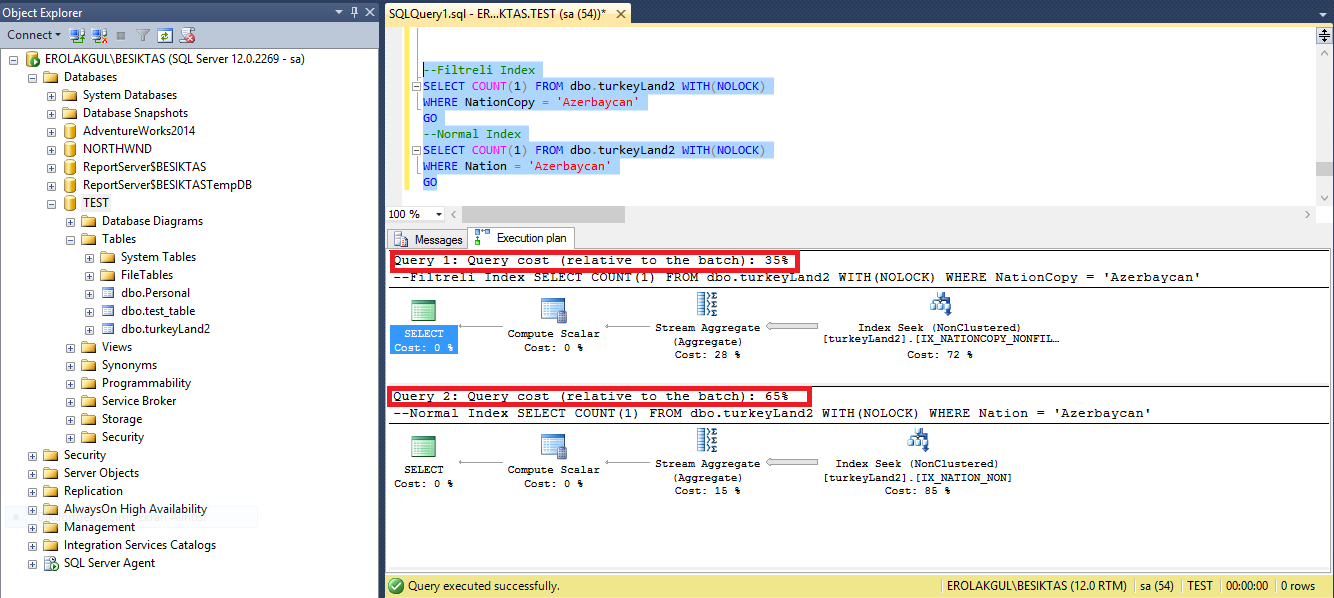
Görüldüğü üzere filtreli index kullanıdığımız veriler üzerinde yapılan işlemlerde maliyet kullanmadığımız yerdeki aynı verilere göre yüzde 53 lük bir düşüş kaydetti(35 e 65) .
Bunu işletmelerde yine en çok kullanılan kolonların özelliklerine göre de uygulayabiliriz.Örneğin kolonlarda 0 ve 1 olarak tutulan veriler vardır ve sizin 1 leri görmeniz gerekiyordur.Filtreyi 1 olarak tutulan kolonların satırlarına uygularsınız yada en çok işlem yaptığınız kısım ‘İstanbul’ lokasyonlu müşterilerinizdir,kısıtlamayı yine bu şekilde yaparak görebilirsiniz.
Filtreyi uyguladığımız kolon where clause ile tanımladığımız yer olmak zorunda değil tabiki de.Filtreyi belirleyip başka kolonlar üzerinde non clustered indexi oluşturmak üzere non-clustered indexleri düşürüyoruz ve yeniden tanımlıyoruz ;

Yeni index i, Nation kolonu üzerinde ‘Azerbaycan’ yazan satırlarının karşısındaki ‘Name’ ve ‘Surname’ kolonlarının satırları üzerine kurduk.Şimdi de buna uygun sorgular atarak maliyet ölçümlerini yapacağız.Böylece .NET çilere yazdıkları kodlarda çalıştıracakları sql kodları için hangisini seçmeleri yönünde önerilerde sunabiliriz..
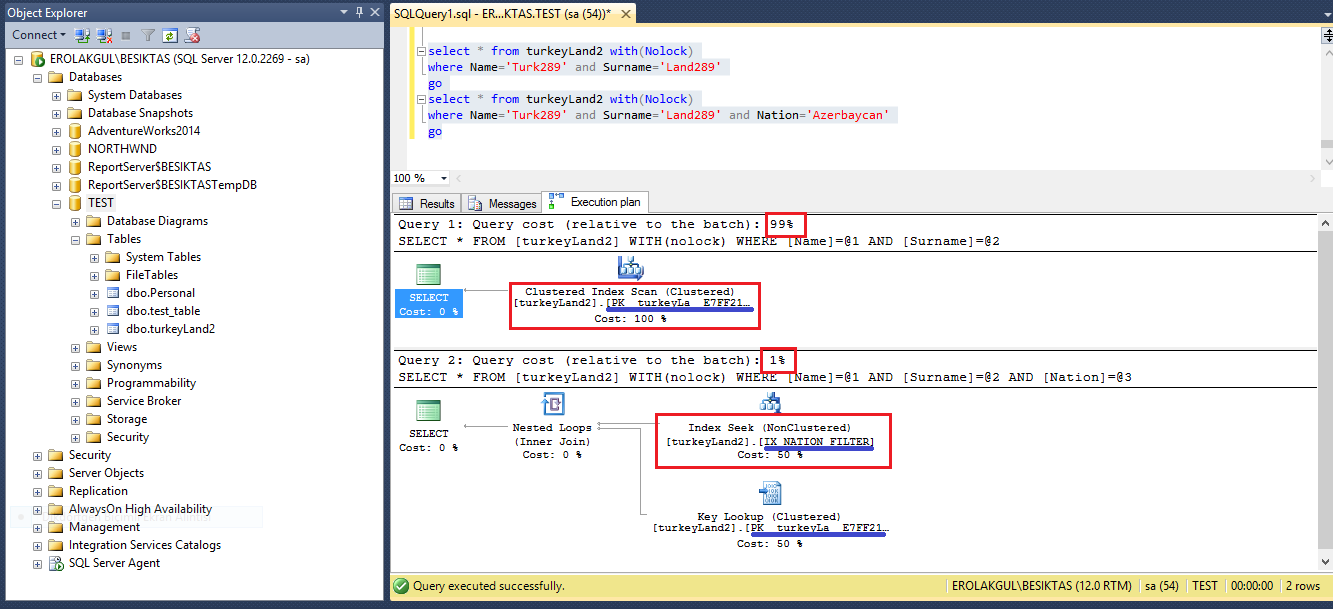
İlk query de sadece isim ve soy isime göre arama yaptırıyorum,ikincisinde ise where clause uyguladığım kolon olan nation ı da katarak işlem gerçekleştiriyorum.
Execution Planı incelediğimde ise ilk sorgunun clustered index üzerinde scan yani tarama işlemi gerçekleştirdiğini ve maliyetinin %99 olduğunu görüyorum diğerine göre.İkinci sorgumun ise non-clustered index arama yaptığını ve key look up yaparak işlemini tamamladığını ve maliyetinin diğerine göre %1 olduğunu görüyorum.Buna göre tavsiye etmemiz gereken ikinci tipe uygun bir query inin sp içinde çağırılması olmalı.
Faydalı olduğunu umarak,bir sonraki yazımızda görüşmek üzere … :)))
